Just chiming in to point out there would be a cost in terms of duplication (multiplied times N). I tend to think "good housekeeping" lends itself better (or at least as good) and will, for the sake of making my point, just describe the portion of my workflow which is geared to address this area of portability.
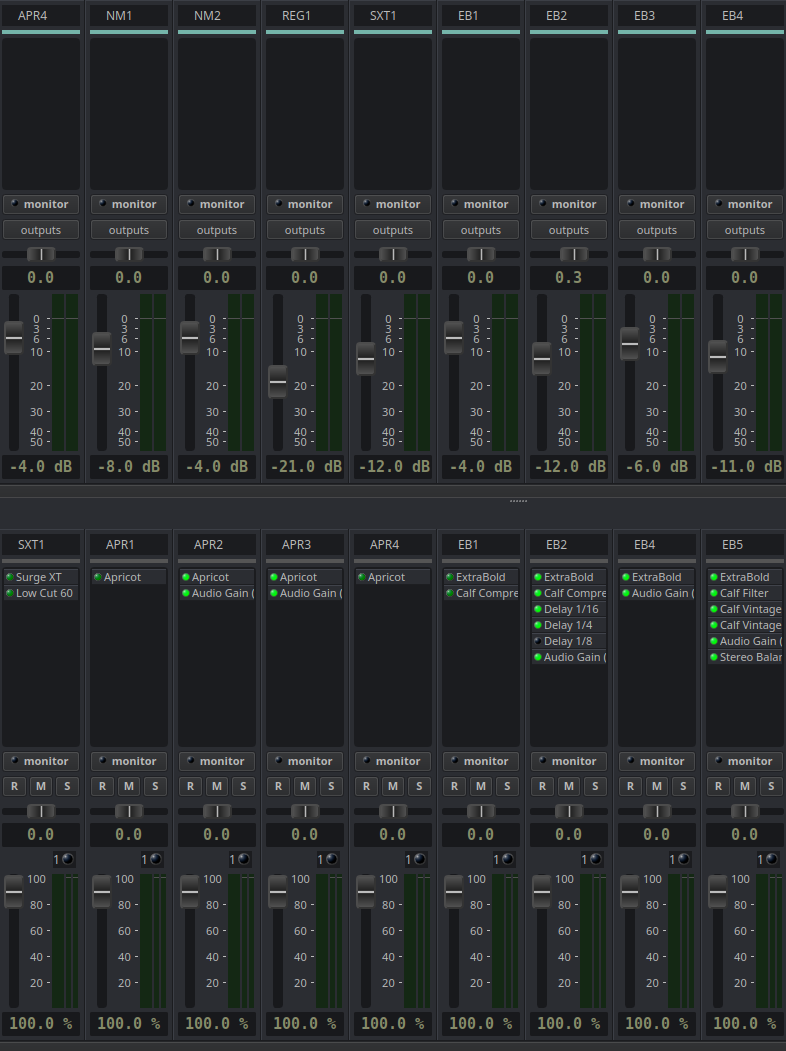
One bus per instrument named using a short mnemonic string formatted as N. Examples would be NM1, NM2, NM3 (Tal NoiseMaker synth instances), ODIN1, ODIN2, ODIN3 (Odin2 synth instances), SF21, SF22, SF23 (sft2 soundfont instances)... you get the idea. The point is, I know what synths I personally like and tend to work with so I'm always going to know what each of these descriptive labels means.
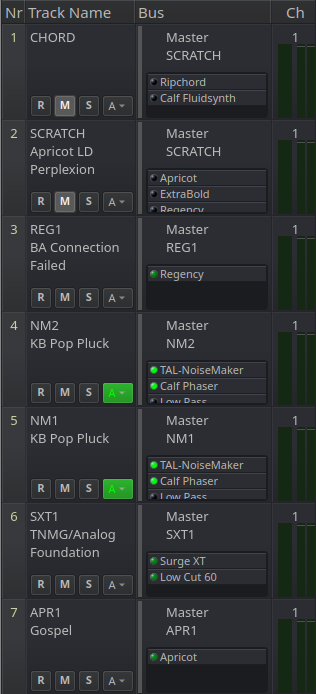
Track names are used to reference both the bus reference (which we've just established serves as a instrument reference) as well as the name of the patch used. I always place the bus reference alone on line 1 in order to end up with a clean mixer and the patch description goes on line 2.
Basically, those 2 ongoing practices essentially "self document" things in a way that allows me to reverse engineer what's needed should I need to revive a project on a system (maybe a new install) where this or that plugin isn't installed. Of course, that's just going to get me up and running for tracks using a default patch.
If a track ends up using a patch that's been customized, that second line is changed to Custom and I take care to go back into the instrument itself and export the patch. The custom patch is exported to a file name like NM1.whatever_extension_is_appropriate and saved to the same directory as the project itself. Now, I've persisted the custom patch and tied it to the project itself...
In the case of Soundfonts, we typically store these in a "central" location for good reason (they're potentially quite large). This is where I would not duplicate the thing and store it alongside my project because I should be backing up my soundfonts (and other central artifacts like 3rd party plugin-specific patches, etc) anyway. Again, the ongoing work used in the project layout steps described above serve to "point the way" in the scenario where we need to recreate. Of course, that's just focused on the layout/recovery side of things. When we need to share our things for collaborative purposes, I've broken that discipline and will export (if needed) and/or duplicate a patch or soundfont as needed but that's all part of a more rare scenario as we tend to collaborate less but should always be thinking about recovery.
I also tend to keep my .mid files in their own session directory because I don't like a cluttered project directory. I do this by editing the .qtr file itself and modifying the <directory> node. A quick mkdir session and moving all .mid files to that location and I'm good to go. Of course, I don't do this right away but soon after a given project feels "legit" and something I know I'll continue to work on. By maintaining a clean project directory, I can maintain a README.txt with any instructions (maybe when I'm collaborating), any custom patches, etc... In other words, those things would be quite difficult to spot if I were to leave dozens or even hundreds of .mid files sitting around. Also, I always create a export directory and use it to write files which are exported after a mix-down. Again, keeping a clean root directory yields big wins. Also, I always run the awesome cleanup function contained in the Files right-click menu after a mix-down/export so things are kept nice and clean.
Here's just a few quick screenshots showing these easy wins in action.
In general, I'd be cautious about asking for these type of work-flow assumptions to be baked in despite the awesome and well intended inspiration. I'd actually say it's the lack of those work-flow assumptions being baked in that provides me with the ability to do what I need to do in order to address these concerns.
and just to throw a monkey wrench in, it might be super cool if Qtractor used a git repo as a data store?
{kind=link}
{kind=link}
{kind=link}
Just chiming in to point out there would be a cost in terms of duplication (multiplied times N). I tend to think "good housekeeping" lends itself better (or at least as good) and will, for the sake of making my point, just describe the portion of my workflow which is geared to address this area of portability.
One bus per instrument named using a short mnemonic string formatted as N. Examples would be NM1, NM2, NM3 (Tal NoiseMaker synth instances), ODIN1, ODIN2, ODIN3 (Odin2 synth instances), SF21, SF22, SF23 (sft2 soundfont instances)... you get the idea. The point is, I know what synths I personally like and tend to work with so I'm always going to know what each of these descriptive labels means.
Track names are used to reference both the bus reference (which we've just established serves as a instrument reference) as well as the name of the patch used. I always place the bus reference alone on line 1 in order to end up with a clean mixer and the patch description goes on line 2.
Basically, those 2 ongoing practices essentially "self document" things in a way that allows me to reverse engineer what's needed should I need to revive a project on a system (maybe a new install) where this or that plugin isn't installed. Of course, that's just going to get me up and running for tracks using a default patch.
If a track ends up using a patch that's been customized, that second line is changed to
Customand I take care to go back into the instrument itself and export the patch. The custom patch is exported to a file name like NM1.whatever_extension_is_appropriate and saved to the same directory as the project itself. Now, I've persisted the custom patch and tied it to the project itself...In the case of Soundfonts, we typically store these in a "central" location for good reason (they're potentially quite large). This is where I would not duplicate the thing and store it alongside my project because I should be backing up my soundfonts (and other central artifacts like 3rd party plugin-specific patches, etc) anyway. Again, the ongoing work used in the project layout steps described above serve to "point the way" in the scenario where we need to recreate. Of course, that's just focused on the layout/recovery side of things. When we need to share our things for collaborative purposes, I've broken that discipline and will export (if needed) and/or duplicate a patch or soundfont as needed but that's all part of a more rare scenario as we tend to collaborate less but should always be thinking about recovery.
I also tend to keep my .mid files in their own
sessiondirectory because I don't like a cluttered project directory. I do this by editing the .qtr file itself and modifying the<directory>node. A quickmkdir sessionand moving all .mid files to that location and I'm good to go. Of course, I don't do this right away but soon after a given project feels "legit" and something I know I'll continue to work on. By maintaining a clean project directory, I can maintain aREADME.txtwith any instructions (maybe when I'm collaborating), any custom patches, etc... In other words, those things would be quite difficult to spot if I were to leave dozens or even hundreds of .mid files sitting around. Also, I always create aexportdirectory and use it to write files which are exported after a mix-down. Again, keeping a clean root directory yields big wins. Also, I always run the awesomecleanupfunction contained in theFilesright-click menu after a mix-down/export so things are kept nice and clean.Here's just a few quick screenshots showing these easy wins in action.
In general, I'd be cautious about asking for these type of work-flow assumptions to be baked in despite the awesome and well intended inspiration. I'd actually say it's the lack of those work-flow assumptions being baked in that provides me with the ability to do what I need to do in order to address these concerns.
and just to throw a monkey wrench in, it might be super cool if Qtractor used a git repo as a data store?
...I'm running away